Continuous data example
Source:vignettes/Continuous_outcome_example.Rmd
Continuous_outcome_example.RmdIntroduction
This is the vignette for performing population adjustment methods with continuous data, in order to compare marginal treatment effects when there are cross-trial differences in effect modifiers and limited patient-level data. We will demonstrate how to apply MAIC, STC, G-computation with ML, G-computation with Bayesian inference and multiple imputation marginalisation. The document structure follow the binary data example vignette which should be referred to for more details.
Example analysis
First, let us load necessary packages.
# install.packages("outstandR",
# repos = c("https://statisticshealtheconomics.r-universe.dev", "https://cloud.r-project.org"))
#
# install.packages("simcovariates",
# repos = c("https://n8thangreen.r-universe.dev", "https://cloud.r-project.org"))
library(boot) # non-parametric bootstrap in MAIC and ML G-computation
library(copula) # simulating BC covariates from Gaussian copula
library(rstanarm) # fit outcome regression, draw outcomes in Bayesian G-computation
library(tidyr)
library(dplyr)
library(MASS)
library(outstandR)
library(simcovariates)Data
We first simulate both the IPD and ALD data. See the binary data
example vignette for more details on how this is implemented. The
difference with that example is that we change the family
argument in gen_data() to
gaussian(link = "identity"), corresponding to the
continuous data case. The gen_data() function is available
in the simcovariates
package on GitHub.
N <- 200
allocation <- 2/3 # active treatment vs. placebo allocation ratio (2:1)
b_trt <- log(0.17) # conditional effect of active treatment vs. common comparator
b_X <- -log(0.5) # conditional effect of each prognostic variable
b_EM <- -log(0.67) # conditional interaction effect of each effect modifier
meanX_AC <- c(0.45, 0.45) # mean of normally-distributed covariate in AC trial
meanX_BC <- c(0.6, 0.6) # mean of each normally-distributed covariate in BC
meanX_EM_AC <- c(0.45, 0.45) # mean of normally-distributed EM covariate in AC trial
meanX_EM_BC <- c(0.6, 0.6) # mean of each normally-distributed EM covariate in BC
sdX <- c(0.4, 0.4) # standard deviation of each covariate (same for AC and BC)
sdX_EM <- c(0.4, 0.4) # standard deviation of each EM covariate
corX <- 0.2 # covariate correlation coefficient
b_0 <- -0.6 # baseline intercept coefficient ##TODO: fixed value
covariate_defns_ipd <- list(
PF_cont_1 = list(type = continuous(mean = meanX_AC[1], sd = sdX[1]),
role = "prognostic"),
PF_cont_2 = list(type = continuous(mean = meanX_AC[2], sd = sdX[2]),
role = "prognostic"),
EM_cont_1 = list(type = continuous(mean = meanX_EM_AC[1], sd = sdX_EM[1]),
role = "effect_modifier"),
EM_cont_2 = list(type = continuous(mean = meanX_EM_AC[2], sd = sdX_EM[2]),
role = "effect_modifier")
)
b_prognostic <- c(PF_cont_1 = b_X, PF_cont_2 = b_X)
b_effect_modifier <- c(EM_cont_1 = b_EM, EM_cont_2 = b_EM)
num_normal_covs <- length(covariate_defns_ipd)
cor_matrix <- matrix(corX, num_normal_covs, num_normal_covs)
diag(cor_matrix) <- 1
rownames(cor_matrix) <- c("PF_cont_1", "PF_cont_2", "EM_cont_1", "EM_cont_2")
colnames(cor_matrix) <- c("PF_cont_1", "PF_cont_2", "EM_cont_1", "EM_cont_2")
ipd_trial <- simcovariates::gen_data(
N = N,
b_0 = b_0,
b_trt = b_trt,
covariate_defns = covariate_defns_ipd,
b_prognostic = b_prognostic,
b_effect_modifier = b_effect_modifier,
cor_matrix = cor_matrix,
trt_assignment = list(prob_trt1 = allocation),
family = gaussian("identity"))
ipd_trial$trt <- factor(ipd_trial$trt, labels = c("C", "A"))Similarly, for the aggregate data but with the additional summarise step (see binary data example vignette for code).
This general format of the data sets are in a ‘long’ style consisting of the following.
ipd_trial: Individual patient data
-
PF_*: Patient measurements prognostic factors -
EM_*: Patient measurements effect modifiers -
trt: Treatment label (factor) -
y: Continuous numeric
ald_trial: Aggregate-level data
-
variable: Covariate name. In the case of treatment arm sample size this isNA -
statistic: Summary statistic name from mean, standard deviation or sum -
value: Numerical value of summary statistic -
trt: Treatment label. Because we assume a common covariate distribution between treatment arms this isNA
Our data look like the following.
head(ipd_trial)
#> id PF_cont_1 PF_cont_2 EM_cont_1 EM_cont_2 trt y true_eta
#> 1 1 0.75056436 0.95597583 0.3158969 1.19430733 C 1.9634929 0.582883524
#> 2 2 0.83246940 0.11789773 0.5094678 0.08180243 A 0.1985888 -1.476422106
#> 3 3 1.13401333 1.15036919 1.2342379 0.74771694 A 1.1820915 0.005184912
#> 4 4 0.78518298 0.83080451 -0.1625820 0.35223227 C 0.3712188 0.520117172
#> 5 5 -0.38547667 0.87070020 0.7213797 -0.03557032 A -1.9387976 -1.760974264
#> 6 6 -0.04851591 -0.03013213 0.6580067 0.05853054 A -1.3363926 -2.139514435There are 4 correlated continuous covariates generated per subject,
simulated from a multivariate normal distribution. Treatment
trt takes either new treatment A or standard of
care / status quo C. The ITC is ‘anchored’ via C, the
common treatment.
ald_trial
#> # A tibble: 16 × 4
#> variable statistic value trt
#> <chr> <chr> <dbl> <chr>
#> 1 EM_cont_1 mean 0.618 NA
#> 2 EM_cont_1 sd 0.406 NA
#> 3 EM_cont_2 mean 0.649 NA
#> 4 EM_cont_2 sd 0.376 NA
#> 5 PF_cont_1 mean 0.662 NA
#> 6 PF_cont_1 sd 0.370 NA
#> 7 PF_cont_2 mean 0.623 NA
#> 8 PF_cont_2 sd 0.389 NA
#> 9 y mean 0.437 C
#> 10 y sd 1.13 C
#> 11 y sum 28.0 C
#> 12 y mean -1.04 B
#> 13 y sd 1.16 B
#> 14 y sum -142. B
#> 15 NA N 64 C
#> 16 NA N 136 BIn this case, we have 4 covariate mean and standard deviation values; and the total, average and sample size for each treatment B and C.
In the following we will implement for MAIC, STC, and G-computation methods to obtain the marginal variance and the marginal treatment effect.
Model fitting in R
The outstandR package has been written to be easy to
use and essential consists of a single function,
outstandR(). This can be used to run all of the different
types of model, which we will call strategies. The first two
arguments of outstandR() are the individual and
aggregate-level data, respectively.
A strategy argument of outstandR takes
functions called strategy_*(), where the wildcard
* is replaced by the name of the particular method
required, e.g. strategy_maic() for MAIC. Each specific
example is provided below.
The formula used in this model, passed as an argument to the strategy function is
lin_form <- as.formula("y ~ PF_cont_1 + PF_cont_2 + trt:EM_cont_1 + trt:EM_cont_2")MAIC
As mentioned above, pass the model specific strategy function to the
main outstandR() function, in this case use
strategy_maic().
outstandR_maic <-
outstandR(ipd_trial, ald_trial,
strategy = strategy_maic(
formula = lin_form,
family = gaussian(link = "identity")))The returned object is of class outstandR.
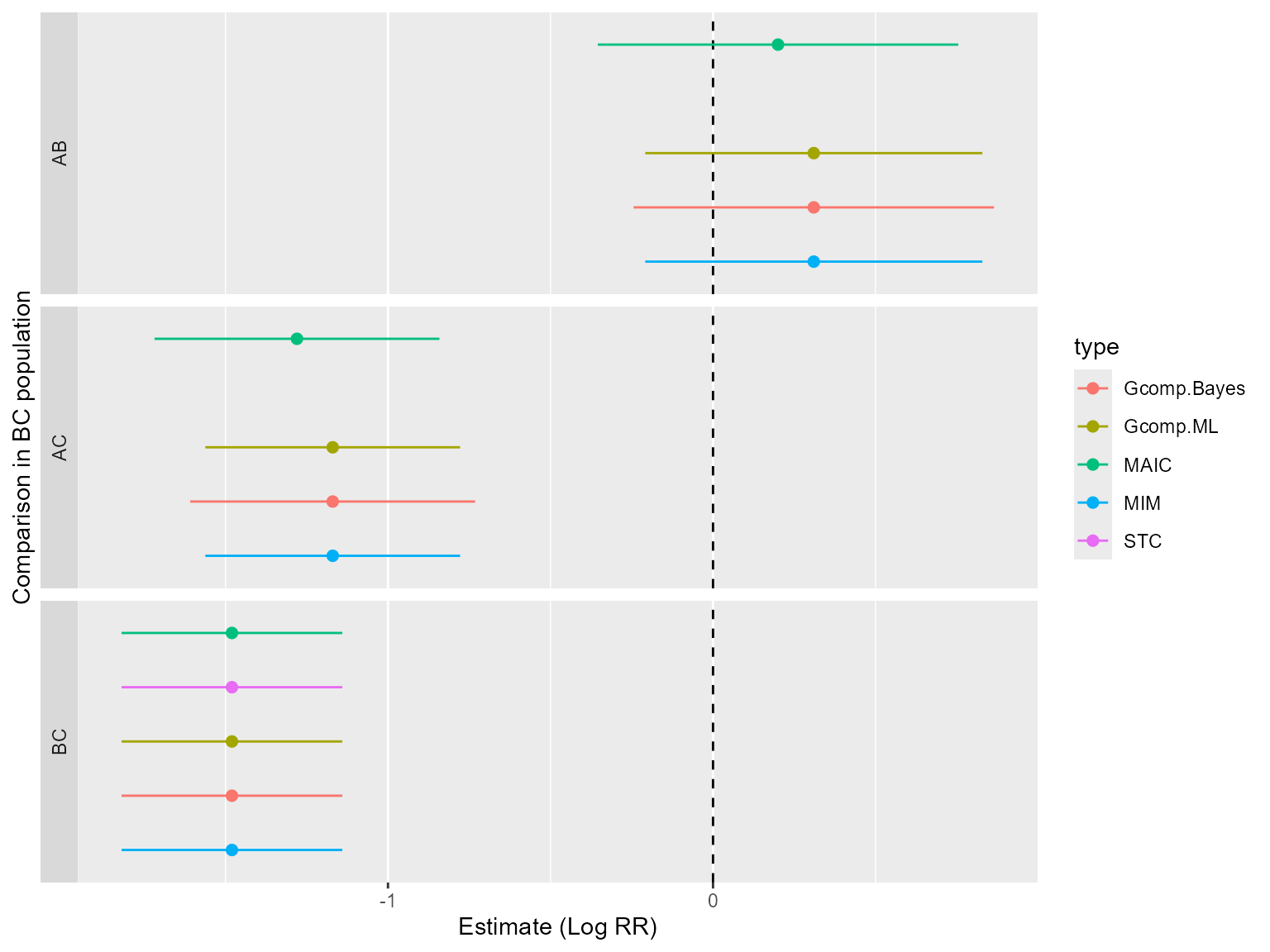
outstandR_maic
#> Object of class 'outstandR'
#> Model: gaussian
#> Scale: mean_difference
#> Common treatment: C
#> Individual patient data study: AC
#> Aggregate level data study: BC
#> Confidence interval level: 0.95
#>
#> Contrasts:
#>
#> # A tibble: 3 × 5
#> Treatments Estimate Std.Error lower.0.95 upper.0.95
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 AB 0.199 0.0798 -0.354 0.753
#> 2 AC -1.28 0.0497 -1.72 -0.845
#> 3 BC -1.48 0.0301 -1.82 -1.14
#>
#> Absolute:
#>
#> # A tibble: 2 × 5
#> Treatments Estimate Std.Error lower.0.95 upper.0.95
#> <chr> <dbl> <dbl> <lgl> <lgl>
#> 1 A -1.14 0.0174 NA NA
#> 2 C 0.139 0.0303 NA NASimulated Treatment Comparison (STC)
STC is the conventional outcome regression method. It involves
fitting a regression model of outcome on treatment and covariates to the
IPD. Simply pass the same as formula as before with the
strategy_stc() strategy function.
outstandR_stc <-
outstandR(ipd_trial, ald_trial,
strategy = strategy_stc(
formula = lin_form,
family = gaussian(link = "identity")))
outstandR_stc
#> Object of class 'outstandR'
#> Model: gaussian
#> Scale: mean_difference
#> Common treatment: C
#> Individual patient data study: AC
#> Aggregate level data study: BC
#> Confidence interval level: 0.95
#>
#> Contrasts:
#>
#> # A tibble: 3 × 5
#> Treatments Estimate Std.Error lower.0.95 upper.0.95
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 AB NaN NA NA NA
#> 2 AC NaN NA NA NA
#> 3 BC -1.48 0.0301 -1.82 -1.14
#>
#> Absolute:
#>
#> # A tibble: 2 × 5
#> Treatments Estimate Std.Error lower.0.95 upper.0.95
#> <chr> <dbl> <dbl> <lgl> <lgl>
#> 1 A NaN NA NA NA
#> 2 C -1.57 NA NA NAParametric G-computation with maximum-likelihood estimation
G-computation marginalizes the conditional estimates by separating
the regression modelling from the estimation of the marginal treatment
effect for A versus C. Pass the
strategy_gcomp_ml() strategy function.
outstandR_gcomp_ml <-
outstandR(ipd_trial, ald_trial,
strategy = strategy_gcomp_ml(
formula = lin_form,
family = gaussian(link = "identity")))
outstandR_gcomp_ml
#> Object of class 'outstandR'
#> Model: gaussian
#> Scale: mean_difference
#> Common treatment: C
#> Individual patient data study: AC
#> Aggregate level data study: BC
#> Confidence interval level: 0.95
#>
#> Contrasts:
#>
#> # A tibble: 3 × 5
#> Treatments Estimate Std.Error lower.0.95 upper.0.95
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 AB 0.314 0.0693 -0.202 0.830
#> 2 AC -1.17 0.0392 -1.56 -0.779
#> 3 BC -1.48 0.0301 -1.82 -1.14
#>
#> Absolute:
#>
#> # A tibble: 2 × 5
#> Treatments Estimate Std.Error lower.0.95 upper.0.95
#> <chr> <dbl> <dbl> <lgl> <lgl>
#> 1 A -0.889 0.0134 NA NA
#> 2 C 0.278 0.0296 NA NABayesian G-computation with MCMC
The difference between Bayesian G-computation and its maximum-likelihood counterpart is in the estimated distribution of the predicted outcomes. The Bayesian approach also marginalizes, integrates or standardizes over the joint posterior distribution of the conditional nuisance parameters of the outcome regression, as well as the joint covariate distribution.
Pass the strategy_gcomp_bayes() strategy function.
outstandR_gcomp_bayes <-
outstandR(ipd_trial, ald_trial,
strategy = strategy_gcomp_bayes(
formula = lin_form,
family = gaussian(link = "identity")))
outstandR_gcomp_bayes
#> Object of class 'outstandR'
#> Model: gaussian
#> Scale: mean_difference
#> Common treatment: C
#> Individual patient data study: AC
#> Aggregate level data study: BC
#> Confidence interval level: 0.95
#>
#> Contrasts:
#>
#> # A tibble: 3 × 5
#> Treatments Estimate Std.Error lower.0.95 upper.0.95
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 AB 0.311 0.0760 -0.229 0.852
#> 2 AC -1.17 0.0459 -1.59 -0.750
#> 3 BC -1.48 0.0301 -1.82 -1.14
#>
#> Absolute:
#>
#> # A tibble: 2 × 5
#> Treatments Estimate Std.Error lower.0.95 upper.0.95
#> <chr> <dbl> <dbl> <lgl> <lgl>
#> 1 A -0.888 0.0165 NA NA
#> 2 C 0.282 0.0305 NA NAMultiple imputation marginalisation
Finally, the strategy function to pass to outstandR()
for multiple imputation marginalisation is
strategy_mim(),
outstandR_mim <-
outstandR(ipd_trial, ald_trial,
strategy = strategy_mim(
formula = lin_form,
family = gaussian(link = "identity")))
outstandR_mim
#> Object of class 'outstandR'
#> Model: gaussian
#> Scale: mean_difference
#> Common treatment: C
#> Individual patient data study: AC
#> Aggregate level data study: BC
#> Confidence interval level: 0.95
#>
#> Contrasts:
#>
#> # A tibble: 3 × 5
#> Treatments Estimate Std.Error lower.0.95 upper.0.95
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 AB 0.312 0.0724 -0.215 0.839
#> 2 AC -1.17 0.0423 -1.57 -0.766
#> 3 BC -1.48 0.0301 -1.82 -1.14
#>
#> Absolute:
#>
#> # A tibble: 2 × 5
#> Treatments Estimate Std.Error lower.0.95 upper.0.95
#> <chr> <lgl> <lgl> <lgl> <lgl>
#> 1 A NA NA NA NA
#> 2 C NA NA NA NA